ABOUT
My journey in Data Engineering and GenAI

Data Engineer | Databricks | Azure | Snowflake | dbt | GenAI Engineer
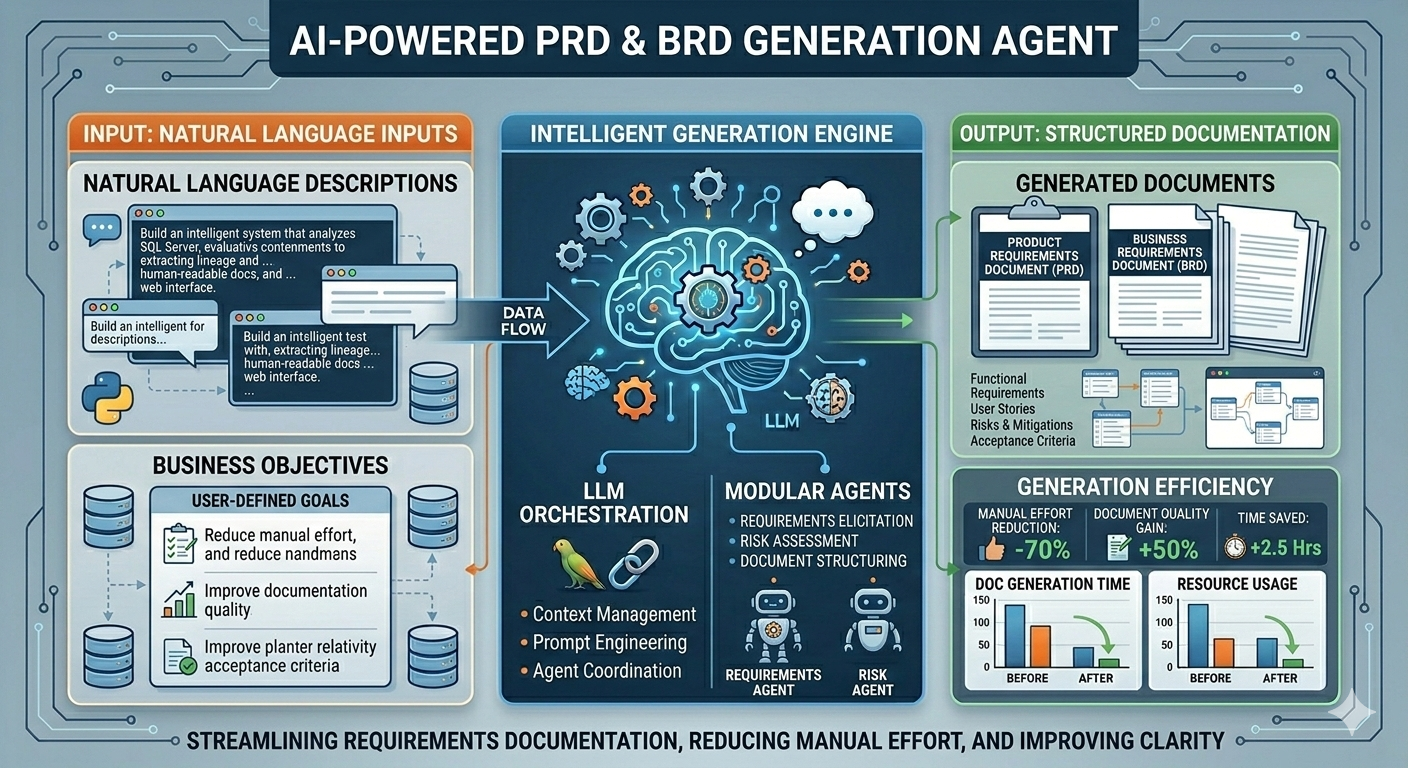
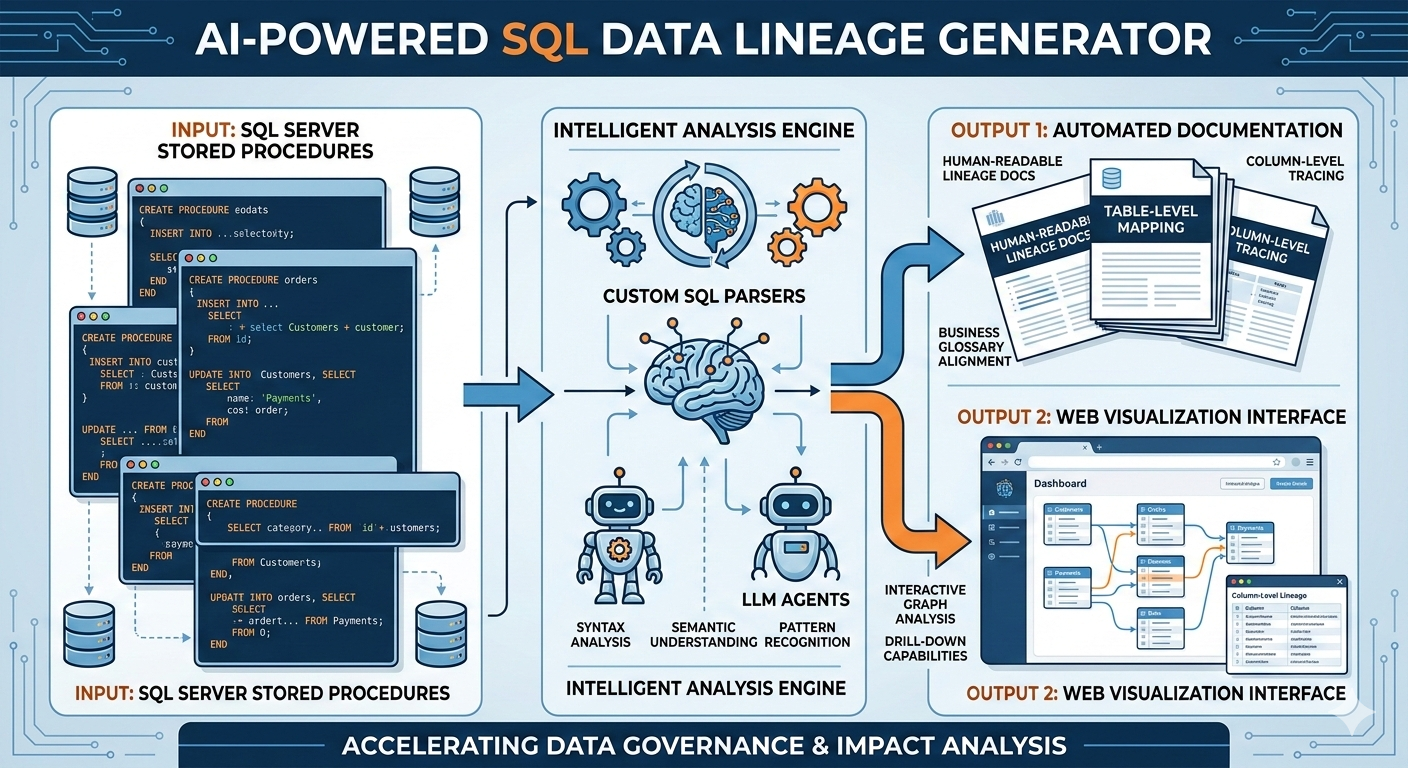
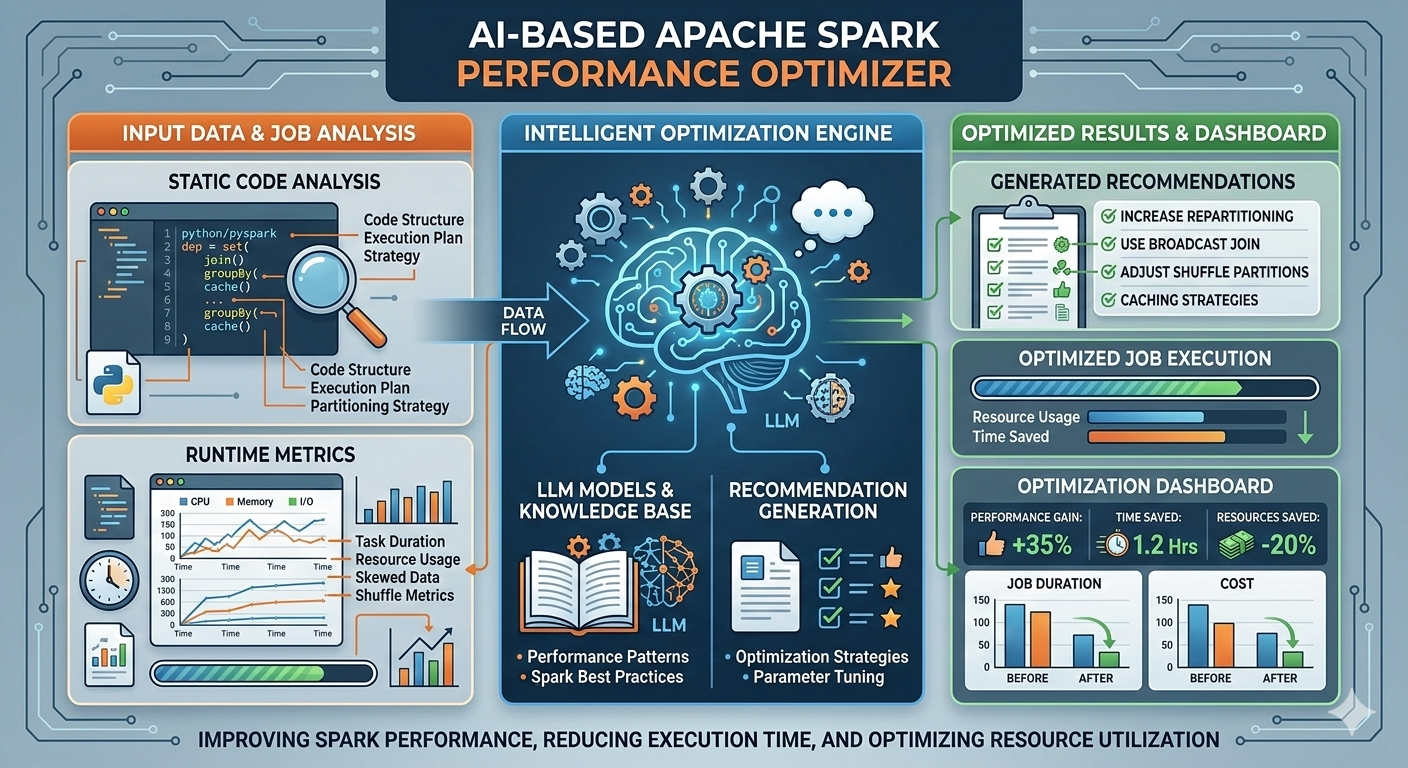
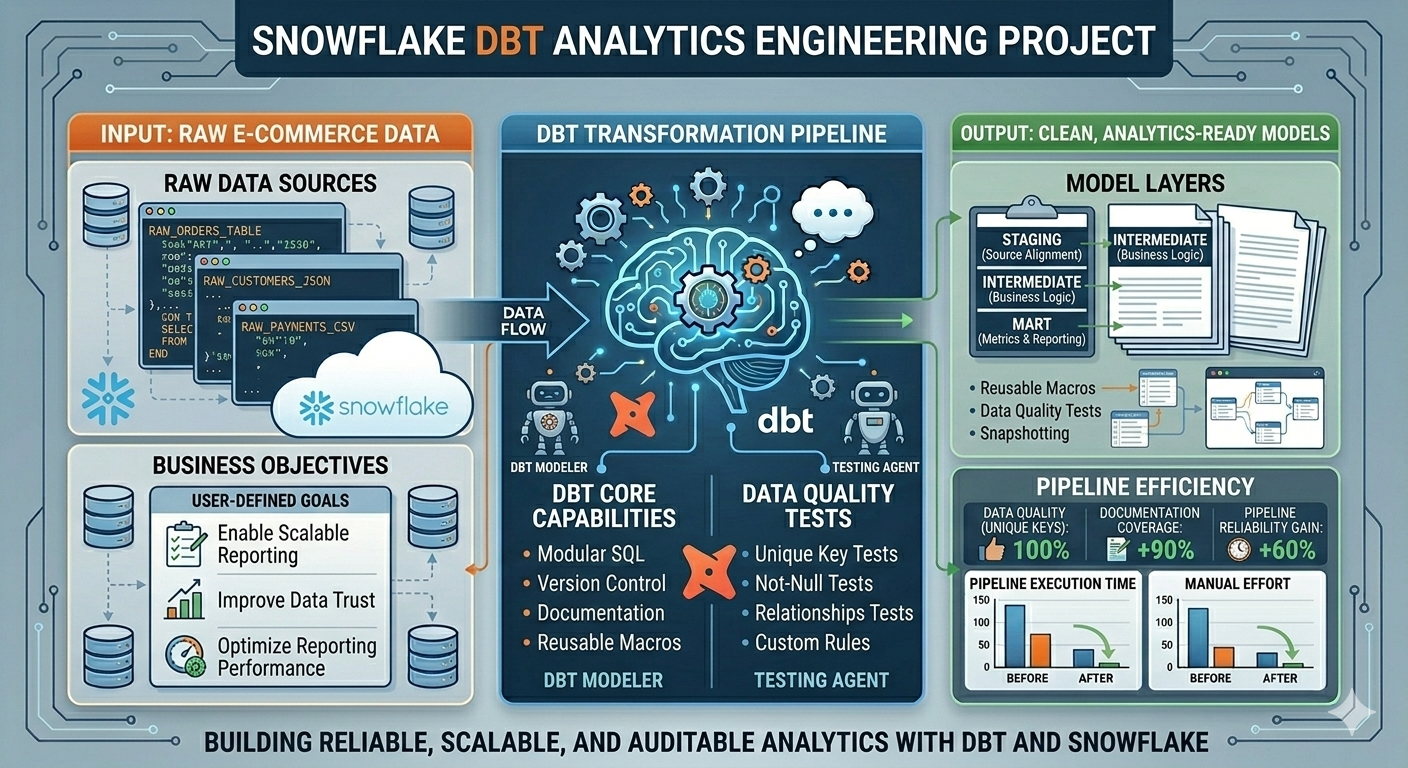
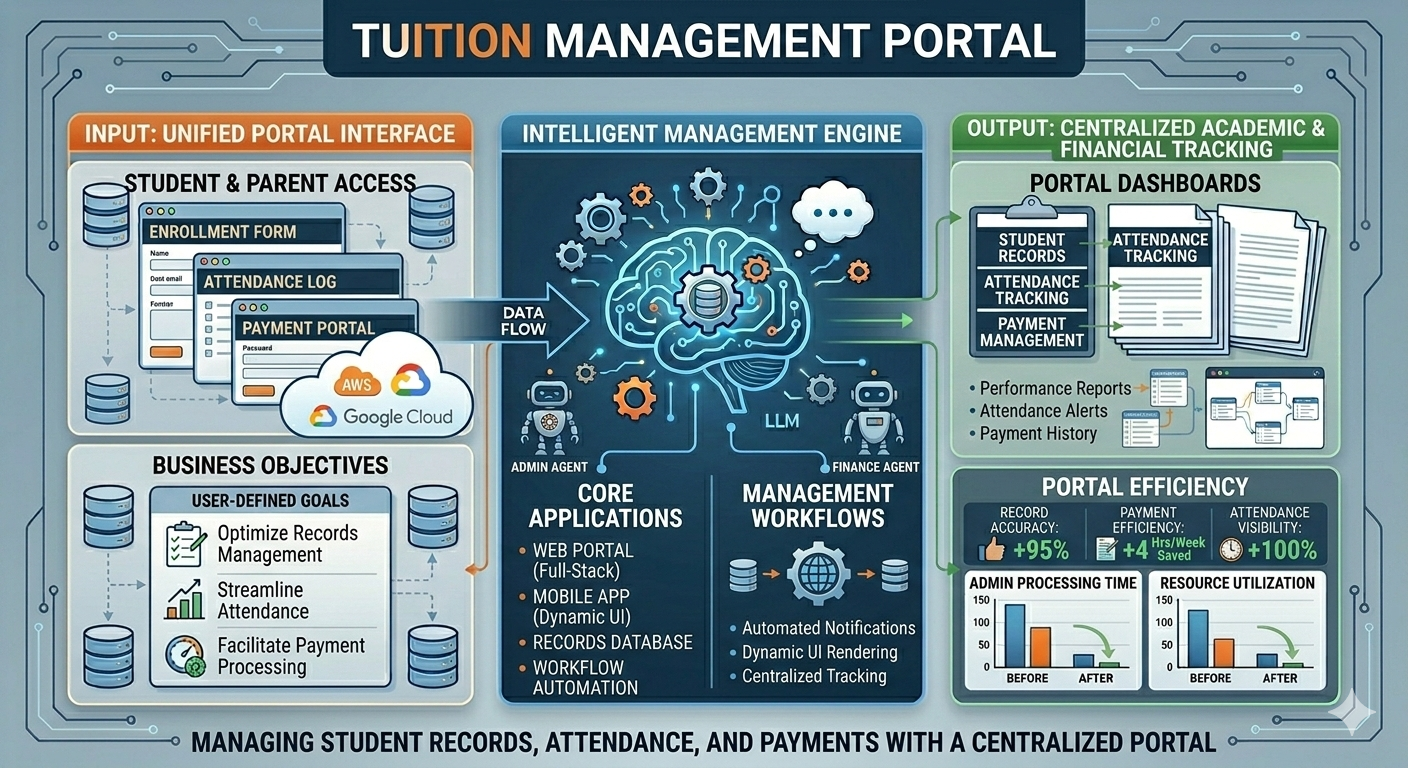
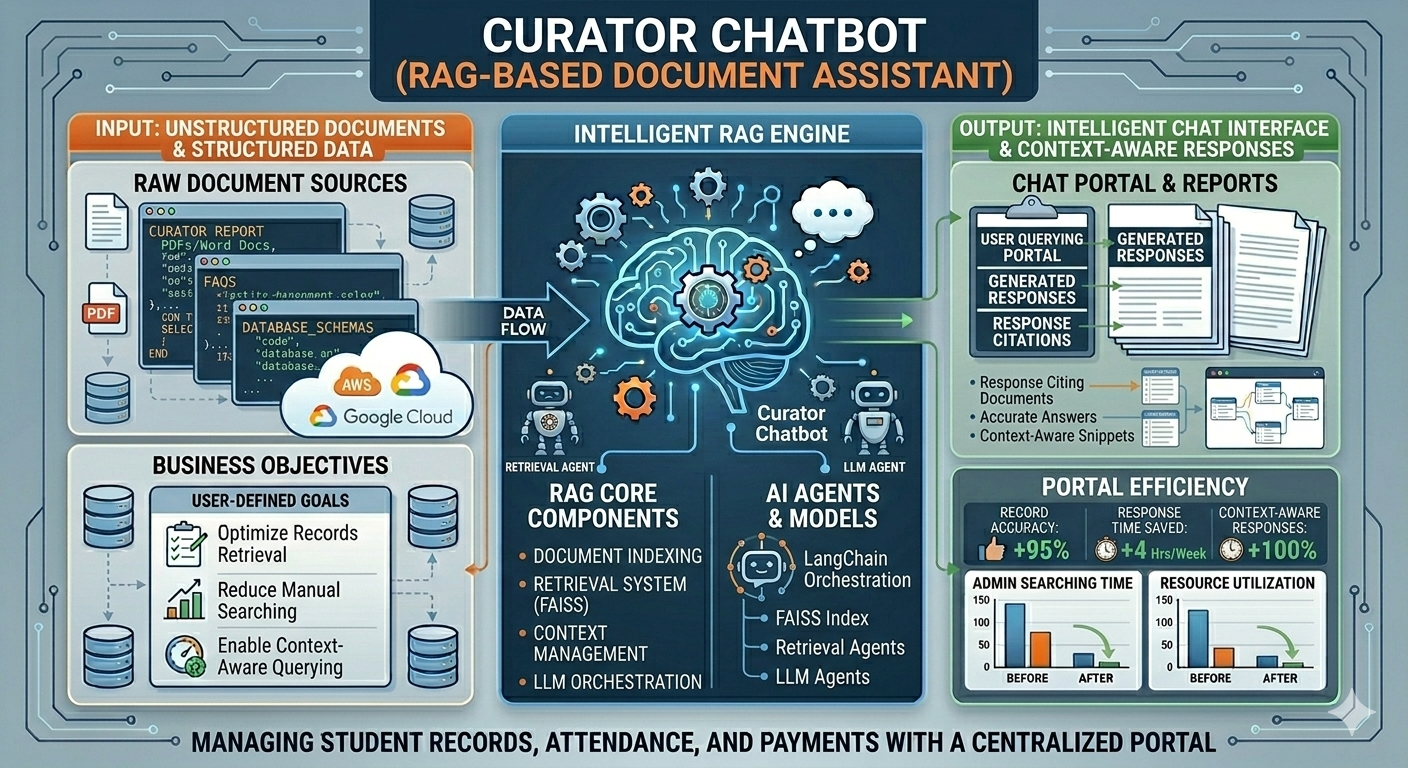
My journey into Data Engineering started with a deep curiosity about how large-scale systems process and transform massive amounts of data efficiently. What began as learning Python and SQL gradually evolved into building real-world data pipelines and working with enterprise-grade data platforms. Currently working as a Data Engineer at Cognizant, I design and develop scalable ETL pipelines and data ingestion frameworks using Databricks and PySpark, enabling efficient processing of healthcare data at scale. I have hands-on experience working across modern data architectures involving Snowflake, dbt, Azure Data Lake Storage Gen2 (ADLS Gen2), and AWS S3, helping build reliable and optimized data platforms. I specialize in building distributed data processing systems using Apache Spark, implementing medallion architecture (Bronze, Silver, Gold), optimizing ETL performance, and ensuring data quality through automated validation frameworks. Alongside Data Engineering, I am actively exploring Generative AI applications, building RAG-based intelligent systems using LangChain and vector databases to automate data workflows and improve engineering productivity. My goal is to design intelligent, scalable, and future-ready data platforms that combine the power of distributed computing, cloud technologies, and AI-driven automation.
- Birthday: 15 Aug 2003
- Phone: +91 8248233162
- City: Chennai, India
- GitHub: github.com/Sridhar1508
- LeetCode: leetcode.com/SRIDHAR1508
- Age: 21
- Degree: B.Tech Information Technology
- Email: sridharmasthan@gmail.com
- LinkedIn: linkedin.com/in/Sridhar1508
DATA ENGINEERING SKILLS
TOOLS & PLATFORMS
- Databricks & Delta Lake
- Snowflake Data Cloud
- dbt (Data Build Tool)
- Azure Data Lake Storage Gen2
- AWS S3 Storage
- Azure Data Factory
- Git, GitHub & Version Control
- Docker & Containerization
- VS Code & PyCharm
- Power BI & Data Visualization
- Postman & API Testing
- Jira & Agile Development